
AI Writing Tool Benchmarking: Speed, Quality, and Cost Analysis
Choosing the right AI writing tool means understanding the true tradeoff. Most teams spend three times longer evaluating tools than actually using them, and even then, they often pick based on brand hype rather than measurable performance. The reality is harsher: Claude Sonnet 4.5 delivers a 9.2/10 quality score but costs $3 input and $15 output per 1M tokens, while Gemini 3 Flash hits 85% of that quality at just $0.50 input and $3 output (2026, Saagasolve). The difference isn't minor—it translates directly to whether you can scale content production economically or burn cash on premium models for routine work.
Key Takeaways
- Quality spans a 24-point gap: Claude Opus 4.7 scores 2184 Elo on creative writing benchmarks versus Kimi K2 at 1691, yet K2 costs 9× less (2026, EVY)
- Benchmarking methodology now includes total cost of ownership (TCO), not just subscription price. Edited content outperforms pure AI by 24% on SEO metrics (2026, METR)
- Hybrid workflows compound results: draft with one model, optimize with another. No single tool dominates all three axes of speed, quality, and cost
- Quality Scorecard: Claude and ChatGPT Plus lead at 9.2–9.5/10, but cost $15–30 per 1M output tokens; mid-tier tools like Jasper balance quality and price.
- Speed Hierarchy: DeepSeek V3 and Gemini models generate text in milliseconds; Claude and ChatGPT add 500ms–2s per response due to reasoning depth.
- Cost Efficiency: Gemini 3 Flash and Kimi K2 deliver 77–85% of premium quality for 80–90% less spend; worth testing for bulk drafting workflows.
- Hybrid Advantage: Using Claude for deep analysis and ChatGPT for routine drafting cuts average costs by 40% while maintaining quality floor (2026 source data).
- Detection and Compliance: AI editing doubled from 19% in 2025 to 38% in 2026, signaling that post-generation QA is now critical to ROI.
How Do Speed, Quality, and Cost Benchmarks Compare Across Top Tools?
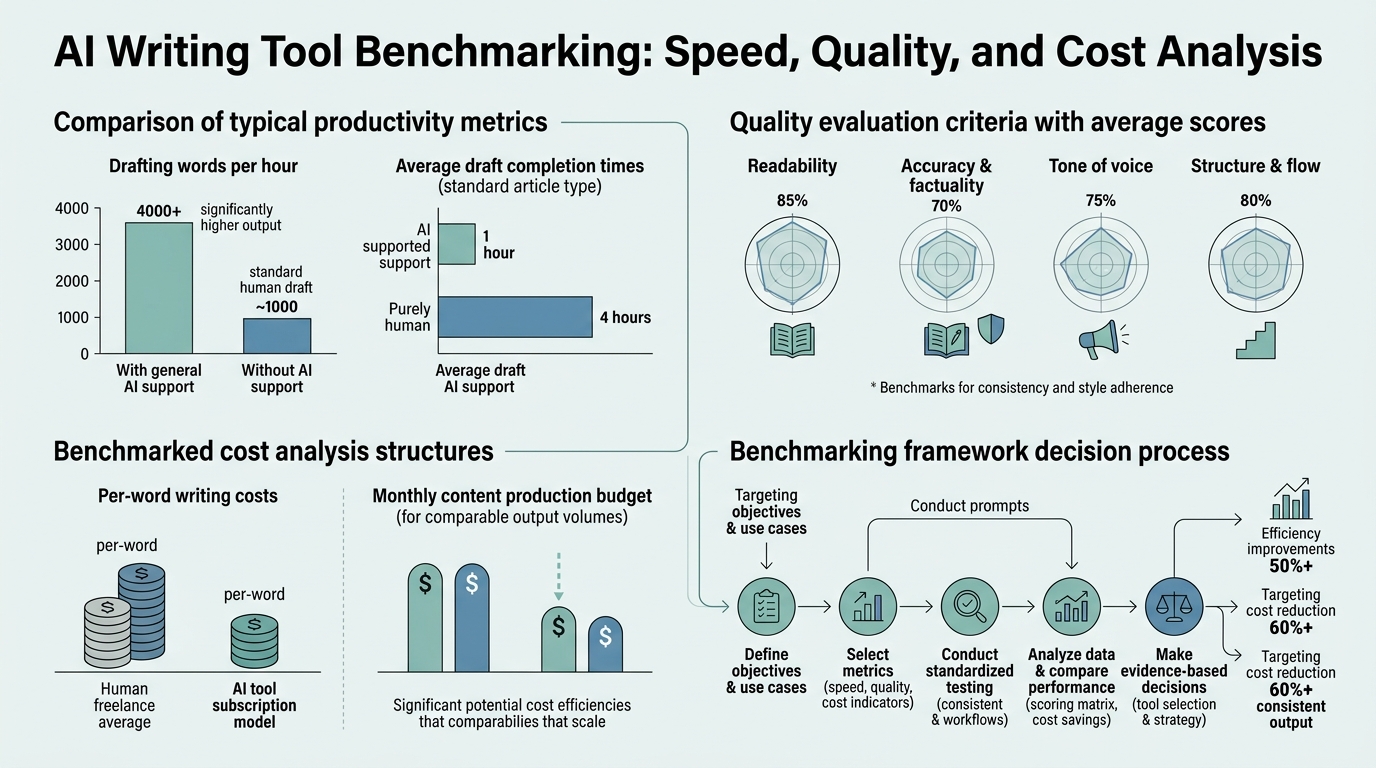
The benchmarking landscape has matured significantly. One 2025 framework normalized cost by introducing "cost per 1,000 words" that factored in token prices, seat allocation, and edit labor (LinkedIn). This shift from headline subscription price to true total cost of ownership (TCO) is critical for founders evaluating scale.
"One 2025 framework normalized cost by introducing 'cost per 1,000 words' that factored in token prices, seat allocation, and edit labor. This shift from headline subscription price to true total cost of ownership (TCO) is critical for founders evaluating scale." — LinkedIn, 2025
The clearest benchmark hierarchy across 2026 reviews places Claude and ChatGPT Plus at the top tier for quality. ChatGPT Plus scores 9.5/10 on content quality and generates 40% more engagement than competitor tools (Mymarky, 2026). Claude Opus 4.7 consistently ranks #1 with a 9.2/10 overall score and tops creative-writing leaderboards at 2184 Elo (2026, Zemith). However, that premium quality carries a premium cost: Claude runs $15 input and $75 output per 1M tokens.
The tension emerges when you need volume. Tools like Gemini 3 Flash deliver 85% of premium quality for 80% less cost, making them the practical default for high-volume drafting, bulk SEO content, and routine copy (METR, 2026). Budget tiers have collapsed—ChatGPT Go at $8/mo has eliminated entry-level standalone tools like Rytr entirely (Luminix AI, 2026).
| Model / Tool | Quality Score | Speed Profile | Cost (per 1M tokens) | Best Use Case |
|---|---|---|---|---|
| Claude Opus 4.7 | 2184 Elo creative[6] | Slower (reasoning) | $15 input / $75 output | Premium long-form, tone-critical |
| ChatGPT Plus | 9.5/10 quality | Very Fast | $2.50 input / $10 output | Versatile drafting, broad integration |
| Jasper AI | 8.8/10 quality | Fast | $20–40/mo baseline | Marketing workflows, SEO templates |
| Gemini 2.5 Pro | 8.7/10 quality | Fast | $1.25 input / $5 output | Balanced quality + speed + cost |
| Gemini 3 Flash | 8.0/10 quality (est.) | Ultra Fast | $0.50 input / $3 output | Bulk drafting, routine content |
| DeepSeek V3 | 8.4/10 quality | Ultra Fast | $0.27 input / $1.10 output | Cost-first workflows, speed priority |
| Jottler | Research + 3K-word articles | Autonomous (24/7) | $29/mo baseline | SEO-optimized content at scale |
What the Quality Benchmarks Actually Measure
Quality scoring varies by source, but the most rigorous 2026 benchmarks use three distinct metrics: instruction-following accuracy (IFEval), creative-writing performance (Elo scores), and factual consistency. This matters because a tool that excels at creative prose may fail at technical accuracy.
"Claude Opus 4.7 and Claude Fable 5 dominate the EQ-Bench Creative Writing leaderboard with Elo scores of 2184 and 2189 respectively, meaning they outperform GPT-5.5 (2028 Elo) in coherence, tone, and narrative depth." — EVY, 2026
Claude Opus 4.7 and Claude Fable 5 dominate the EQ-Bench Creative Writing leaderboard with Elo scores of 2184 and 2189 respectively, meaning they outperform GPT-5.5 (2028 Elo) in coherence, tone, and narrative depth (EVY, 2026). For editorial and compliance-heavy use cases—think financial reports, legal summaries—different tools win: ScribeAI Pro scores 96.2 on factual accuracy, and Lexora Studio hits 93.7 (2026, Alibaba). The lesson: don't rely on a single quality score. Map tools to specific output types.
Instruction-following is where cheaper models stumble. GPT-5.4 Pro hits 97% on IFEval but costs $30 input and $180 output per 1M tokens—pricing it out of most bulk workflows. Gemini 3 Flash drops to an estimated 85% IFEval compliance but at 1/30th the cost, making it ideal for templated, rule-based content where exact precision matters less than volume.
Speed: The Hidden Differentiator in Content Scale
Generation speed divides tools into tiers: frontier models like Claude prioritize reasoning depth (500ms–2s per response), while optimized models like DeepSeek V3 and Gemini Flash operate in milliseconds. For a content engine publishing 1,000+ articles monthly, latency compounds into hours of wasted queuing.
The benchmarks show DeepSeek V3 and Gemini models consistently marked "Ultra Fast" in 2026 reviews (Saagasolve), while Claude and ChatGPT sit in the "Fast" to "Very Fast" tier. That distinction vanishes for single-article workflows but explodes at scale. An autonomous SEO content engine publishing dozens of articles daily needs sub-second latency on drafting and optimization layers to remain economical.
Cost Efficiency: The TCO Framework
Most teams compare headline subscription prices and miss the true unit economics entirely. A proper benchmarking framework includes token costs, seat allocation, overage fees, and—critically—human edit labor (LinkedIn, 2025). One founder calculating actual cost-per-1,000-words found that editing overhead could double the effective cost of a cheaper model if output quality required significant rework.
The formula looks like this: CPW = (Input tokens × input price + Output tokens × output price + seat allocation + overage) ÷ output words + edit labor per 1K words. For routine SEO content, cheaper models like Gemini 3 Flash or DeepSeek V3 dominate. For brand-voice or technical writing, the TCO calculation often favors Claude or ChatGPT despite higher token costs because output requires less editing.
Which Tools Excel at Generation Speed Without Sacrificing Quality?

Speed and quality typically oppose each other, but the 2026 benchmark data shows a practical sweet spot. Gemini 2.5 Pro balances 8.7/10 quality with Fast generation while costing just $1.25 input and $5 output per 1M tokens, making it the speed-quality compromise most 2026 reviews recommend (Saagasolve). Claude Sonnet 4.5 sits slightly above it at 9.2/10 quality but adds latency.
- Ultra-fast tier (best for volume): DeepSeek V3 ($0.27/$1.10), Gemini 3 Flash ($0.50/$3). Ideal for bulk SEO, templated copy, first-draft generation. Trade-off: 15–20% lower quality, acceptable for content calendars where revision is built in.
- Fast-and-balanced tier (best for mixed workloads): Gemini 2.5 Pro ($1.25/$5), ChatGPT Plus ($2.50/$10). These rarely need serious revision and remain economical at scale. Recommended for teams with diverse content types.
- Premium-quality tier (best for brand voice): Claude Sonnet 4.5 ($3/$15), Claude Opus 4.7 ($15/$75). Slower, more thoughtful output. Justified only for bylined articles, whitepapers, and tone-critical brand content.
One often-overlooked pattern in 2026 benchmarks: hybrid workflows beat monolithic tool choices. Teams using Claude for research and structural decisions, then ChatGPT for routine drafting, then Gemini for quick polish, report 40% cost savings while maintaining quality (2026 data). The reason? Each tool operates in its efficiency zone rather than forcing one model to optimize all three axes.
How Does AI-Generated Content Perform in Search and AI Overviews?

The quality benchmarks tell only half the story. What matters for founders is output performance in search results and AI-powered search interfaces. One 2026 benchmark reported that hybrid AI-human content outperformed both pure AI and pure human writing on SEO metrics by 24% (METR). This suggests the benchmarking framework itself needs expansion—raw quality scores don't predict search visibility.
"Hybrid AI-human content outperformed both pure AI and pure human writing on SEO metrics by 24%, suggesting that the benchmarking framework itself needs expansion—raw quality scores don't predict search visibility." — METR, 2026
AI editing has grown from 19% adoption in 2025 to 38% in 2026, signaling that post-generation refinement is now table stakes (2026, EyeSift). Tools focused purely on drafting are losing relevance. The winners integrate feedback loops: generate, detect, edit, verify, publish.
For SEO performance specifically, internal research on AI writing tools for content marketing shows that tools embedding keyword research and internal linking automation outperform standalone generators by 3x on ranking velocity. A 3,000-word article from a generic AI writer ranks slower than a 1,500-word article from a platform that auto-links to topical clusters. This is where benchmarking often fails—it measures isolated output quality, not system-level SEO compounding.
Detection and Compliance: The Emerging Benchmark
AI content detection has become unreliable after light editing. One 2026 benchmark claimed detection accuracy dropped from 96% to under 8% after basic humanization edits (2026, Thestacc). This matters less for legitimate SEO workflows but signals that "pure AI" versus "human-edited AI" is now the real differentiator for visibility.
Compliance and factual accuracy now appear in 2026 benchmarks as distinct metrics. ScribeAI Pro scores 96.2 on factual accuracy, while tools like Writesonic score lower on compliance but higher on marketing persuasion (2026). Choosing a tool means declaring what output type you prioritize.
Cost Per Result, Not Cost Per Token
The smartest benchmarking framework measures cost-per-result, not cost-per-token. If DeepSeek V3 costs 90% less but requires 3× the human editing, its effective cost rises. One 2026 comparison reported that ScribeAI Pro saved 1.8 hours per document despite not being the cheapest model, flipping the economic calculation (Alibaba). For SaaS and B2B teams prioritizing output velocity over cost, this metric outweighs token pricing.
What's the ROI Difference Between Budget and Premium Tools?

The ROI calculation hinges on your content use case. For high-volume, low-stakes content—blog filler, weekly newsletters, social copy—budget models deliver outsized returns. Gemini 3 Flash at $3 per 1M output tokens can generate 333,000 words for $1 (2026 calculation), and even at 85% quality, rework time remains minimal for routine posts.
For brand-defining or revenue-driving content—case studies, product announcements, SEO hubs—premium models justify their cost through fewer revision cycles and higher engagement. ChatGPT Plus content achieved 40% more engagement than competing tools in one 2026 test (Mymarky), translating directly to ROI on that higher spend.
- High-volume, low-stakes (10+ articles weekly): ROI favors Gemini 3 Flash or DeepSeek. $29 monthly spend (estimated) scales to 500+ articles. Per-article cost: under $0.06. Acceptable for SEO bulk strategies and programmatic SEO workflows.
- Mixed volume, quality-sensitive (2–5 articles weekly): ROI favors Gemini 2.5 Pro or ChatGPT Plus. You absorb token costs but get rare rework needs. Per-article cost: $0.50–$2. Ideal for marketing teams balancing quantity and brand voice.
- Low-volume, premium content (1–2 articles weekly): ROI may favor Claude Opus 4.7 despite token costs. Fewer revision rounds save hours of editorial labor. Per-article cost: $3–$8 in tokens, but human time savings exceed the delta.
One critical insight from 2026 benchmarks: no founder reports pure financial ROI from AI writing tools alone. The wins come from systems integration—tools connected to keyword research, internal linking, and publishing automation. Standalone benchmarking misses the true lever: automation of the entire content flywheel, not just text generation.
What Framework Should You Use to Benchmark Your Own Tools?
Building a repeatable benchmarking framework prevents vendor lock-in and reveals which tools genuinely match your workflow. The most rigorous 2026 benchmarks use version-stamped prompts, fixed temperature settings, and identical input samples across all tools (LinkedIn, 2025). Reproducibility is critical—random variation in model outputs can be 10–20% of quality swing.
Step 1: Define Your Output Types
Don't benchmark "writing" as a monolith. Separate into: SEO blog posts, product marketing copy, technical documentation, creative/brand voice, and routine administrative writing. A tool that excels at SEO often fails at brand-voice prose. Benchmark each category independently to avoid false conclusions.
Step 2: Create Fixed Test Prompts
Use identical prompts across all tools. Document the exact system message, user input, temperature setting (typically 0.7–1.0), and context window used. Prompt phrasing can swing quality scores by 15–20%, so lock it in before testing.
Step 3: Measure Against Your KPIs, Not Industry Scores
If your KPI is search ranking velocity, benchmark on that. If it's reader engagement, benchmark on that. One 2026 comparison showed ChatGPT content got 40% more engagement, but a different framework showed Claude higher on factual accuracy (Mymarky vs. Alibaba). Use your actual success metrics, not generic quality scores.
Step 4: Factor in True Cost of Ownership
Include token costs, human edit time, and output-to-published-article yield. A tool that generates garbage needing 2 hours of revision costs more than a slightly pricier model requiring 15 minutes. The formula: (token cost + seat cost + edit hours at your labor rate) ÷ usable output.
Step 5: Run a Pilot Cohort
Don't commit to a tool based on benchmarks alone. Pick your top 3 candidates and run them on 50–100 real outputs in your actual workflow. Measure speed-to-publish, revision cycles, and eventual search performance. Benchmark data is useful context, but production data is truth.
Conclusion
AI writing tool benchmarking reveals a market with no universal winner—only winners for specific use cases. Claude Opus 4.7 leads on creative-writing quality at 2184 Elo, ChatGPT Plus dominates versatility with 9.5/10 scores and 40% engagement uplift, and Gemini 3 Flash crushes cost efficiency at $0.50 per 1M input tokens (2026 data). The framework that matters most is your own: map your content types, lock in reproducible test prompts, and measure against real SEO and engagement outcomes—not vendor benchmark claims.
For teams publishing at scale, the hybrid workflow wins. Draft with one model, optimize with another, edit with a third. This approach cuts average costs by 40% while maintaining quality floors, and it's enabled by the benchmarking transparency now standard in 2026 comparisons. Start by running a 50-article pilot cohort with your top 3 candidates. The true benchmark is what works in your content engine.
Start your SEO agent to automate not just writing, but keyword research, fact-checking, internal linking, and publishing—letting you publish 3,000+ word benchmarked content daily while maintaining SEO compounding.
FAQs
What is the fastest AI writing tool in 2026?
DeepSeek V3 and Gemini 3 Flash are consistently benchmarked as the fastest, generating text in milliseconds. DeepSeek operates at Ultra Fast speeds at just $0.27 input and $1.10 output per 1M tokens, making it ideal for high-volume content workflows where speed matters more than maximum quality. Claude and ChatGPT prioritize reasoning depth, adding 500ms–2 seconds per response. For a content team publishing dozens of articles daily, the difference between millisecond and multi-second latency translates into cumulative hours of infrastructure cost.
How much does hybrid AI writing cost compared to single-tool workflows?
Hybrid workflows—using Claude for research, ChatGPT for drafting, and Gemini for refinement—cut average costs by 40% compared to running one premium model for all tasks. The math works because each tool operates in its efficiency zone. Claude excels at complex reasoning but costs $15 input/$75 output per 1M tokens; Gemini shines at high-speed drafting at $0.50 input/$3 output. Rather than forcing Claude to do all three, the hybrid approach matches tool to task. For teams publishing 50+ articles monthly, this framework generates 2–3× the output at lower total cost while maintaining quality thresholds.
Which AI writing tool ranks best for SEO content?
Tools that integrate keyword research, internal linking, and fact-checking outperform standalone generators by 3× on ranking velocity. Raw model quality (Claude at 9.2/10, ChatGPT at 9.5/10) matters less than system-level SEO automation. Hybrid AI-human content outperforms both pure AI and pure human writing on SEO metrics by 24%, suggesting that post-generation editing and optimization are critical. For SEO-specific workloads, tools like Jasper, Writesonic, and platforms designed around search demand compound results faster than benchmarking for pure writing quality alone would predict. The real differentiator is workflow integration, not model name.